| Item | Value |
|---|---|
| Records | 33,381 |
| Coverages | SUR, HOS, 2CI, CAN |
| Underwriting span | 23.04 ~ 25.09 |
| Calendar span | 23.04 ~ 25.09 |
장기 건강보험 손해율 예측을 위한 새로운 프레임워크
Stage-Adaptive Chain Ladder
1 서론
손해보험의 지급준비금 적립(reserving) 업무는 수십 년간 Chain Ladder 방법에 의존해 왔고, 그중 Mack의 접근법이 업계 표준으로 자리잡았다. Chain Ladder는 본래 “특정 사고연도에 발생한 손해가 이후 수년에 걸쳐 어떻게 신고·정산되는지를 추적” 하기 위해 설계되었다. 즉 해당 사고연도의 보험료는 이미 확정되어 있고, 사고 발생도 그 연도에 끝났다고 가정하며, 남은 손해액의 정산 흐름만을 확률적 대상으로 본다.
이 전제 위에서 Chain Ladder는 손해액만 다루고 보험료는 외생적으로 주어진 것으로 처리하며, 시간이 충분히 지나면 Triangle(사고연도 × 정산 경과 기간)이 언젠가 닫히는 것이 자연스럽다. age-to-age factor·재귀적 분산 공식·꼬리 인자(tail factor) 등 수학적 장치는 모두 이 단기 담보 + run-off 종결 구조 위에 서 있다.
장기 건강보험 — 입원, 수술, 암, 2대 중증질환 담보 등 — 은 이 틀과 맞지 않는다. 계약이 수십 년에 이르는 동안 보험금이 계속 발생하고, 보험료 또한 계약 기간 내내 납입되어 누적된다. 즉 사고연도에 끝나는 것은 보험금 발생도, 보험료 확정도 아니다.
또한 장기 건강보험 계약이 실제 유지되는 기간은 분석을 위해 관측된 기간보다 훨씬 길다. 예를 들어 2025년 1월에 인수된 20년 계약 코호트는 2026년 1월 시점에 겨우 1년치 경험만 관측된 상태이고, 나머지 19년은 모두 예측 대상이다. 따라서 실무적으로 Triangle이 닫히기가 쉽지 않으며, Chain Ladder가 전제하는 ‘run-off 종결’ 조건을 실질적으로 만족시키기 어렵다.
본 문서는 이 현실에 비교적 더 적합하다고 판단하는 필자의 아이디어 Stage-Adaptive Chain Ladder를 소개한다. 핵심은 코호트의 성숙도에 따라 추정 방식을 바꾸는 것이다. 초기 단계에서는 누적 보험료를 기준 분모로 삼는 익스포저 기반(exposure-driven, ED) 추정을 사용하고, 코호트 자체 경험이 신뢰할 수 있게 성숙하면 Chain Ladder로 전환한다.
목표 수량은 최종 손해액(ultimate loss)이 아니다 — 장기 건강보험에서 이 값은 의미 있게 관측되지 않는다. 대신 증분 손해 발생이 지속적 익스포저 누적에 비해 느려지면서 코호트가 수렴하는 안정 손해율 수준이 추정 대상이 된다.
프레임워크는 필자가 개발한 패키지 lossratio로 구현되어 있다. 본 문서는 필자의 논리를 요약하고, 핵심 수식을 제시하며, 대표적인 수술담보 포트폴리오에서 방법을 시연한다.
2 구조적 문제
이후 전개되는 수식은 모두 Triangle의 셀 \(C_{i,k}\)에 대한 것이다. 행 \(i\)는 인수 코호트(예: 인수월), 열 \(k\)는 경과 기간(예: 경과월)을 나타내며, 좌상단의 채워진 영역은 관측된 경험, 우하단의 빈 영역은 예측으로 채워야 할 셀이다. 이후 등장하는 \(C^L_{i,k}\)(누적 손해액)와 \(C^P_{i,k}\)(누적 위험보험료)는 같은 \((i,k)\) 좌표 위에 값만 달리해 올린 두 개의 Triangle(누적 손해액 Triangle, 누적 위험보험료 Triangle)로 이해하면 된다.
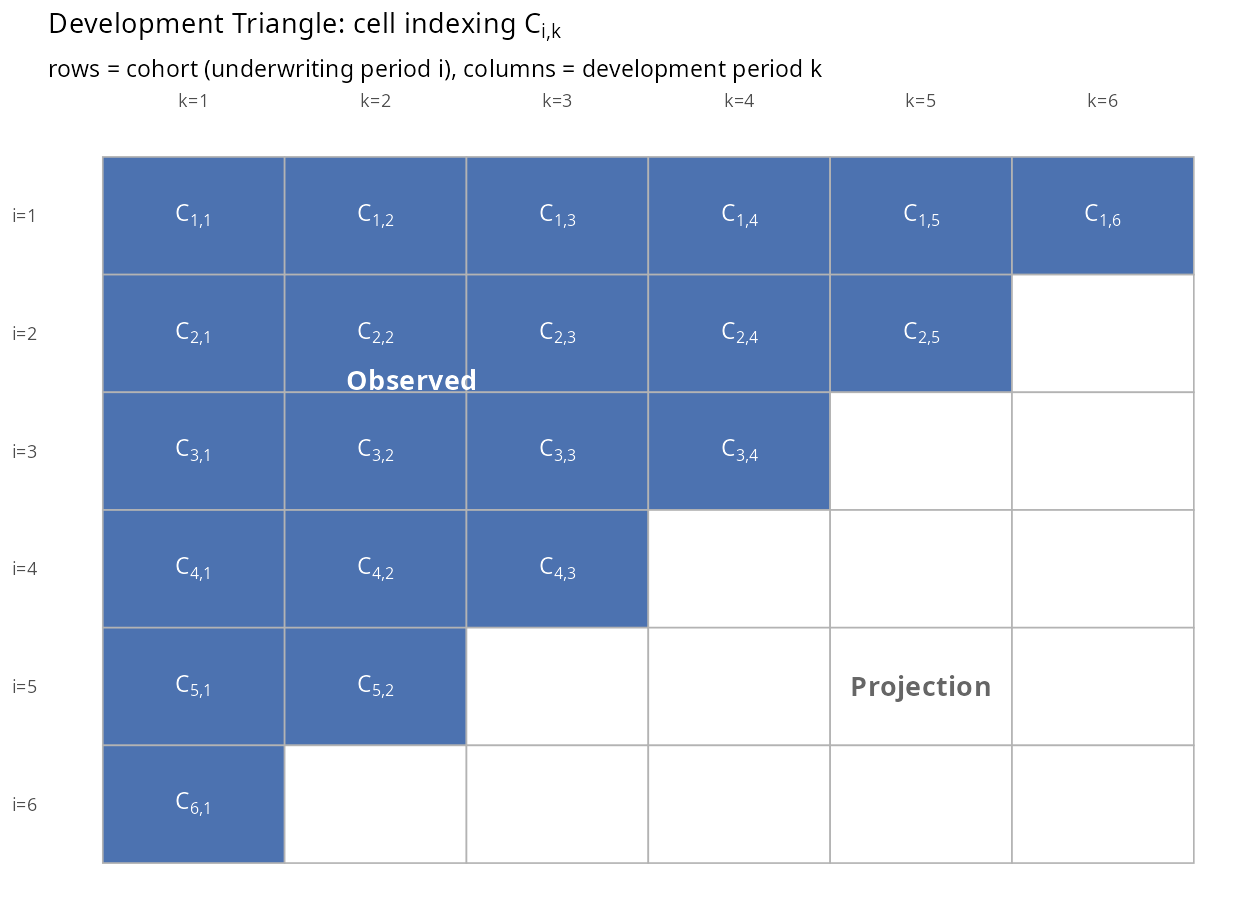
2.1 Chain Ladder의 장기 담보 적용 한계
Mack의 Chain Ladder 재귀식
\[ \widehat{C}^L_{i,k+1} \;=\; \hat{f}_k \cdot \widehat{C}^L_{i,k} \]
은 각 코호트의 예측을 코호트 자체의 누적 손해액 \(C^L_{i,k}\)에 고정시킨다. age-to-age factor \(\hat{f}_k\)는 코호트 전체로부터 추정되지만, 그것이 적용되는 시작값은 각 코호트의 개별 값이다. 관측 이력이 긴 성숙 코호트에서는 잘 작동한다: \(C^L_{i,k}\)가 충분히 실현된 경험을 반영해 신뢰할 수 있는 기준점 역할을 하고, 승법 재귀가 노이즈가 아닌 진짜 코호트 간 차이를 보존한다.
그러나 관측 기간이 짧은 신생 코호트에서는 \(C^L_{i,k}\)가 노이즈와 초기에 발생한 이례적인 지급 보험금에 의해 지배된다. 최종적으로는 같은 손해율 수준으로 수렴할 두 코호트가 초기 누적 손해액에서는 수십에서 수백 퍼센트까지 차이날 수 있다 — 단순히 보험금 신고가 확률적이고 소수 사건에 집중되기 때문이다. 이 노이즈에 이후 \(\hat{f}_k\) 값들을 곱해가면 예측 매 단계에 노이즈가 그대로 전파된다.
장기 건강보험은 이 문제를 세 가지 방식으로 복합적으로 악화시킨다:
대부분의 코호트가 신생이다. 최근 5년간 인수된 포트폴리오를 앞으로 20년간 예측하는 경우, 전형적인 코호트는 자연 발전 수평선의 1/4만 관측한 상태이다. Chain Ladder 기준점이 거의 모든 곳에서 약하다.
최종 손해액이 경험적으로 잘 정의되지 않는다. \[ \widehat{C}^L_{i,\infty} \;=\; C^L_{i,k_{\text{obs}}} \cdot \prod_{j=k_{\text{obs}}}^{\infty} \hat{f}_j \]
관측 기간이 전체 run-off의 일부만 포함하는 상황에서는, 위 공식의 \(\prod_{j=k_{\text{obs}}}^{\infty} \hat{f}_j\) 중 관측되지 않은 미래 기간의 \(\hat{f}_j\) 는 데이터로 뒷받침되지 않는다. 이 부분은 외부 가정(꼬리 인자, tail factor)으로 채워 넣을 수밖에 없으며, 그 가정값이 사실상 최종 손해액 추정치를 결정한다. 즉 장기 수평선에서 제시되는 최종 손해액 수치는 사실상 꼬리 가정이 결정하는 값에 가깝다.
분산이 곱셈으로 누적된다. Mack의 분산 공식은 매 단계마다 불확실성을 \(\hat{f}_k^2\) 배로 곱해가며 전파한다. 덧셈이 아니라 곱셈 누적이라, 20년 같은 긴 수평선에서는 폭이 급격히 확대된다. 결과적으로 얻어지는 신뢰구간이 그대로 제시하면 의사결정에 활용하기 어려울 만큼 넓어지는 경향이 있다.
2.2 데이터가 실제로 보여주는 것
장기 건강보험 데이터에서 일관되게 관찰되는 패턴은 누적 손해액이 아니라 손해율이 안정화된다는 사실이다. 보험료는 유효 익스포저에 비례해 대체로 계속 누적된다. 손해는 코호트가 성숙함에 따라 0에 가까워지는 발전 패턴을 따른다. 누적 손해율(cumulative loss ratio) \(clr_{i,k} = C^L_{i,k} / C^P_{i,k}\) 은 그에 따라 안정적 수준 — 포트폴리오의 장기 손해율 — 으로 접근하며, 분자와 분모가 모두 계속 커져도 그 비율은 수렴한다.
이 관찰이 목표 전환의 동기이다: 최종 손해액이 아니라 안정 손해율을 추정해야 한다.
3 Stage-Adaptive Chain Ladder
3.1 초기 단계: 익스포저 기반 가법 추정 (ED, exposure-driven)
이하 본 문서에서 ED는 exposure-driven의 약어로, 누적 익스포저(≈ 누적 위험보험료)를 기준 분모로 삼아 증분 손해를 가법적(additive) 으로 누적해 설명한다는 의미이다. 핵심 변경은 간단하다. 한 기간의 증분 손해를 누적 손해액이 아니라 누적 익스포저에 비례한다고 본다는 것이다:
\[ E\!\left(\Delta C^L_{i,k+1} \,\middle|\, \mathcal{F}_{i,k}\right) \;=\; g_k \cdot C^P_{i,k}, \]
여기서 \(\mathcal{F}_{i,k}\)는 코호트 \(i\)가 경과 기간 \(k\)까지 관측한 정보 집합(filtration)을, \(C^P_{i,k}\)는 경과 기간 \(k\)에서의 누적 위험보험료를, \(g_k\)는 익스포저 단위당 증분 손해 강도를 나타낸다. 강도는 코호트 전체에 걸쳐 익스포저를 가중치로 삼는 비율 추정량(ratio estimator)으로 풀링된다. 이는 \(\alpha = 1\)(Poisson형) 분산 구조 가정 하에서 가중최소제곱(WLS) 추정량과 동치이다:
\[ \hat{g}_k \;=\; \frac{\sum_i \Delta C^L_{i,k+1}}{\sum_i C^P_{i,k}}. \]
이 추정량의 결정적 속성은 공통의 익스포저 분모를 통해 코호트 간 정보를 빌려온다는 것이다. 세 경과 기간만 관측된 신생 코호트는 자신의 부분 정보를 포트폴리오 수준의 \(\hat{g}_k\)에 기여하고, 동일한 풀링 강도로 예측된다. 그 자체의 노이즈가 큰 \(C^L_{i,k}\)는 기준점으로 쓰이지 않는다; 기준점은 표본 변동이 훨씬 작은 포트폴리오 수준 익스포저이다.
대응되는 분산 구조는
\[ \text{Var}(\Delta C^L_{i,k+1} \mid \mathcal{F}_{i,k}) \;=\; \sigma^2_k \cdot (C^P_{i,k})^{\alpha}, \]
이며 \(\alpha = 1\)(Poisson형)이 기본값이고, \(\alpha = 2\)는 Gamma형, \(1 < \alpha < 2\)는 Tweedie형에 해당한다. 분산 전파는 가법적이다:
\[ \text{Var}(\widehat{C}^L_{i,K}) \;=\; \sum_{k=0}^{K-1} \sigma^2_k \cdot (C^P_{i,k})^{\alpha}. \]
3.2 성숙 단계: 손해 기반 승법 추정 (CL, Chain Ladder)
이하 본 문서에서 CL은 Chain Ladder의 약어로, 코호트 자체의 누적 손해액을 기준으로 다음 기간을 승법적(multiplicative) 으로 예측한다는 의미이다. 다음 절에서 정의할 성숙점 \(k^*\) 이후 구간에서는 age-to-age factor \(\hat{f}_k\)가 충분히 안정되어 풀링된 ED 추정량보다 코호트 자체의 \(C^L_{i,k}\)가 더 신뢰할 수 있는 요약이 된다. 이 구간의 age-to-age factor는 코호트 전체에 걸쳐 풀링하여 추정한다:
\[ \hat{f}_k \;=\; \frac{\sum_i C^L_{i,k+1}}{\sum_i C^L_{i,k}}. \]
이를 사용한 승법 재귀식
\[ \widehat{C}^L_{i,k+1} \;=\; \hat{f}_k \cdot \widehat{C}^L_{i,k} \]
이 가짜가 아닌 진짜 코호트 간 차이를 보존한다. 이 단계의 분산은 Mack을 따른다:
\[ \text{Var}(C^L_{i,k+1} \mid C^L_{i,k}) \;=\; \sigma^2_k \cdot (C^L_{i,k})^{\alpha}. \]
3.3 두 단계를 가르는 경계: 성숙점 \(k^*\) (maturity point)
ED와 CL 중 어느 쪽을 사용할지는 사전에 고정된 경계가 아니라 데이터로부터 경험적으로 결정된다. 성숙점 \(k^*\)는 age-to-age factor의 변동계수와 상대표준오차가 모두 임계값 이하로 떨어지고 그 상태가 일정 기간 연속해서 유지되는 최초의 링크로 정의한다:
\[ CV(\hat{f}_k) < \theta_{cv} \quad \text{and} \quad RSE(\hat{f}_k) < \theta_{rse} \]
이 조건이 최소 \(m\)개의 연속 링크에 대해 모든 \(k \ge k^*\)에서 성립해야 한다. 여기서 \(CV\)는 코호트 간 관측 팩터의 변동계수, \(RSE\)는 WLS 추정치의 상대표준오차이다.
임계값 \(\theta_{cv}\), \(\theta_{rse}\), \(m\)은 모형 가정이 아니라 사용자가 조정 가능한 튜닝 파라미터이다. 패키지 기본값은 다수 실제 포트폴리오에서 합리적으로 작동하지만, 임계값 변경이 결과를 어떻게 움직이는지에 대한 민감도 검토는 실무 적용 시 병행해야 한다. 이는 모형 자체의 약점이 아니라, 전환 시점 선택이 투명하고 조정 가능하다는 설계 특징이다.
\(k^*\)는 담보별로 상이하다. 예를 들어 수술담보는 \(k^* = 4\) 경과월 수준으로 일찍 안정화되는 반면, 암담보는 \(k^* = 13\) 이상이 필요할 수 있다. 프레임워크는 이 이질성을 담보별 파라미터 조정 없이 — 동일한 임계값이 담보별 진단 곡선에서 평가되기 때문에 — 자연스럽게 수용한다.
직관적으로 \(k^*\)는 “예측의 기준점이 포트폴리오 수준 익스포저에서 코호트별 누적 손해액으로 전환되는 시점” 에 대한 경험적 대리변수(proxy)로 이해할 수 있다.
3.4 혼합 규칙
성숙점 \(k^*\)를 경계로, Stage-Adaptive 예측 규칙은:
\[ \widehat{C}^L_{i,k+1} \;=\; \begin{cases} \widehat{C}^L_{i,k} + \hat{g}_k \cdot \widehat{C}^P_{i,k} & k < k^* \quad \text{(ED 단계)} \\[6pt] \hat{f}_k \cdot \widehat{C}^L_{i,k} & k \ge k^* \quad \text{(CL 단계)} \end{cases} \]
전환은 값에서 연속이다: 동일한 \(\widehat{C}^L_{i,k^*}\)가 ED의 출력이자 CL의 입력 역할을 한다. 예측 메커니즘만 바뀐다 — 가법적·익스포저 기반에서 승법적·손해액 기반으로 — 그것도 후자가 신뢰할 수 있게 되는 정확한 시점에서.
이 분해에는 직관적 해석이 있다:
코호트 자체 경험을 신뢰할 수 없을 때는 포트폴리오 수준 익스포저로 예측한다. 코호트 자체 경험이 신뢰할 수 있게 되면 그 경험이 스스로 말하게 한다.
3.5 안정 손해율
장기 담보에서 최종 누적 손해액은 의미 있는 목표가 아니다. 자연스러운 목표는 누적 손해율
\[ clr_{i,k} \;=\; \frac{C^L_{i,k}}{C^P_{i,k}}, \]
이며, 이는 경과 기간 \(k\)가 커지며 \(g_k \to 0\)으로 감쇠할 때 안정화된다. 코호트의 안정 손해율은 극한
\[ clr^*_i \;=\; \lim_{k \to \infty} clr_{i,k}. \]
실무적으로 \(clr^*_i\) 는 고려하는 가장 긴 경과 기간의 예측값, 또는 그 이후의 예측 변화가 무시할 만한 첫 시점에서 읽어낸다. 이 수량이 프레임워크가 궁극적으로 추정하고자 하는 대상이다.
4 실증 예제
대표적인 포트폴리오 데이터로 프레임워크를 시연한다. 네 가지 장기 담보를 포함한다: 수술(SUR), 입원(HOS), 2대 중증질환(2CI), 암(CAN).
본 예제는 네 가지 담보 중 수술담보(SUR)를 중심으로 전개한다. 초기 보험금 강도가 매우 빠르게 나타나고 안정 손해율 수준이 이례적으로 높은 담보여서, 운영상 중요도와 프레임워크 거동 설명의 적합성을 모두 갖춘다. 다른 세 담보(HOS, 2CI, CAN)는 단계 6 ‘담보 간 비교’ 에서 함께 다룬다.
4.1 단계 1: 발전 구조 생성
dev_sur <- build_dev(data[cv_nm == "SUR"], cv_nm)결과로 얻는 dev 객체는 각 코호트-경과 쌍에 대해 누적 손해액 \(C^L_{i,k}\), 누적 보험료 \(C^P_{i,k}\), 증분 손해액 \(\Delta C^L_{i,k+1}\), 손해율 \(clr_{i,k}\)를 보유한다.
모형을 적합하기 전에 원본 코호트 궤적을 먼저 확인하는 것이 유용하다. 각 인수월 코호트의 누적 손해율을 경과월 축에 나란히 그리면:
plot(dev_sur)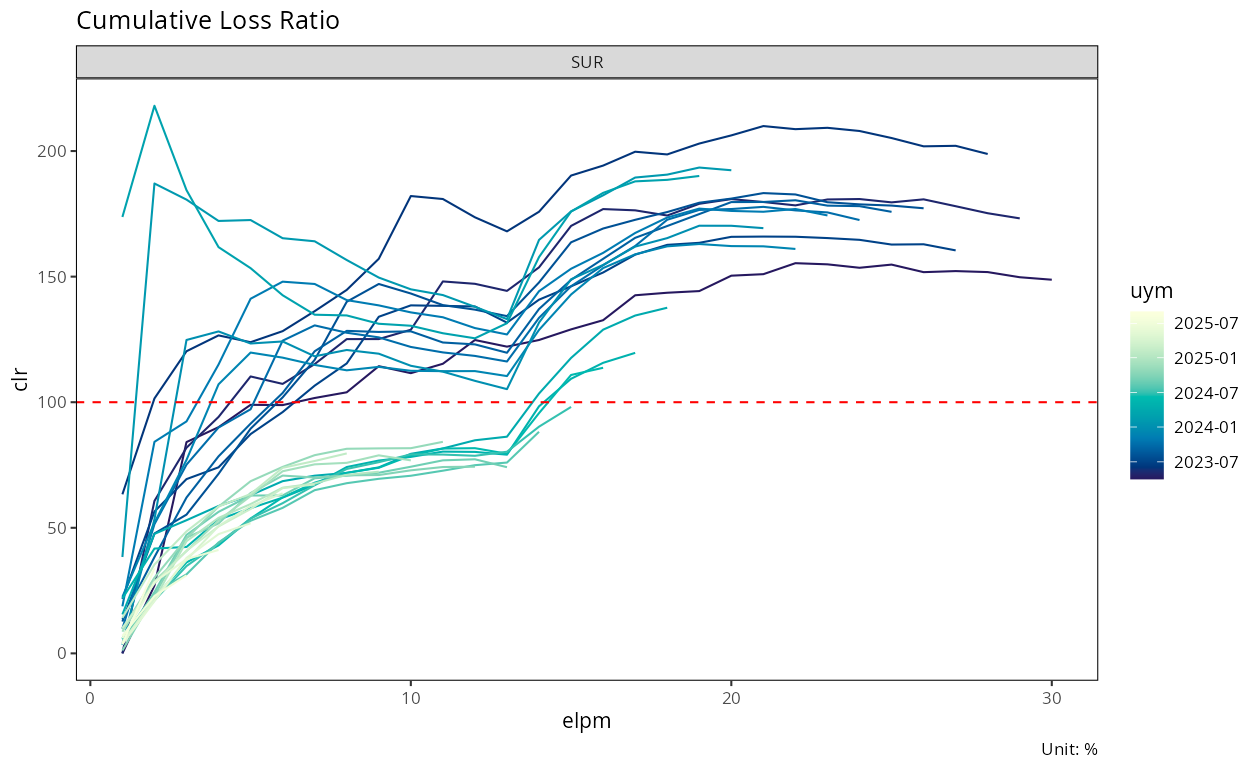
이 그래프 하나만으로도 모형 없이 두 가지 사실이 드러난다. 첫째, 2023년 초기 코호트는 이미 150-200% 수준에서 안정화되었다. 둘째, 2025년 최근 코호트는 아직 발전 초기 구간에 머물러 30-80% 범위에 분포한다. 코호트별로 궤적이 서로 다르지만, 성숙 구간에서는 유사한 수준으로 수렴하는 경향이 보인다.
평균적인 패턴을 함께 확인하려면 summary = TRUE 옵션으로 코호트 평균·중앙값·가중평균 곡선을 overlay한다:
plot(dev_sur, summary = TRUE)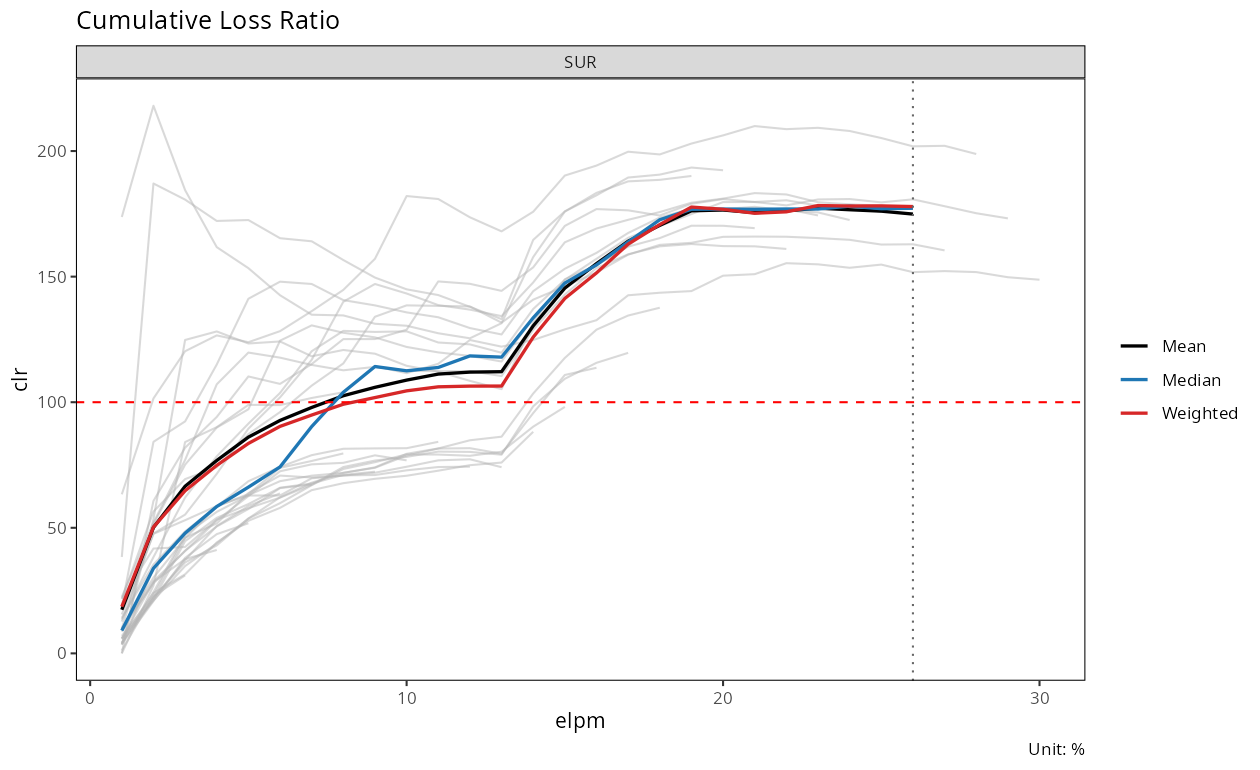
summary_min_n 이하로 떨어지는 경과월을 표시한다.세 요약 곡선이 서로 근접하게 움직인다는 것은 각 경과 시점의 코호트 간 분포가 크게 치우치지 않았음을 의미한다. 세로 점선 오른쪽 구간은 기여 코호트 수가 적어 요약값이 불안정하므로 해석에 주의해야 한다.
이렇게 원본 데이터가 드러내는 패턴을 먼저 확인한 뒤, 프레임워크가 이를 어떻게 구조적으로 해석·예측하는지로 넘어간다.
4.2 단계 2: 혼합 모형 적합
단일 함수 호출로 전체 파이프라인이 수행된다: age-to-age factor 구축, ED 강도 적합, 성숙점 \(k^*\) 검출, 단계별 적절한 분산 계산, 신뢰구간 산출. bootstrap = TRUE 옵션은 분석적 델타법 구간을 모수적 부트스트랩 백분위 구간으로 대체하며, 작은 익스포저에서 비율 변환의 편향 보정이 더 우수하다.
fit_sur <- fit_lr(
dev_sur,
method = "hybrid",
bootstrap = TRUE,
B = 1000,
seed = 42
)
print(fit_sur)<lr_fit>
method : hybrid
loss_var : closs
exposure_var : crp
loss_alpha : 1
exposure_alpha: 1
delta_method : simple
conf_level : 0.95
ci_type : bootstrap (B = 1000, seed = 42)
sigma_method : min_last2
recent : all
maturity[SUR] : 4
groups : cv_nm
periods : 30 SUR에서 검출된 성숙점은 \(k^* = 4\) 경과월로, 수술 보험금 발생이 유난히 일찍 안정화된다는 것을 의미한다. 단 4개월 후에 age-to-age factor 시퀀스가 안정성 임계값을 통과하고, 예측 메커니즘이 풀링 익스포저 기반 강도에서 코호트별 Chain Ladder로 전환된다.
4.3 단계 3: 예측 손해율 검토
주요 산출물은 인수 코호트별 예측 누적 손해율이다. 관측된 경험은 실선, 혼합 예측은 점선, 음영 띠는 95 % 부트스트랩 백분위 신뢰구간이다.
plot(fit_sur, type = "clr")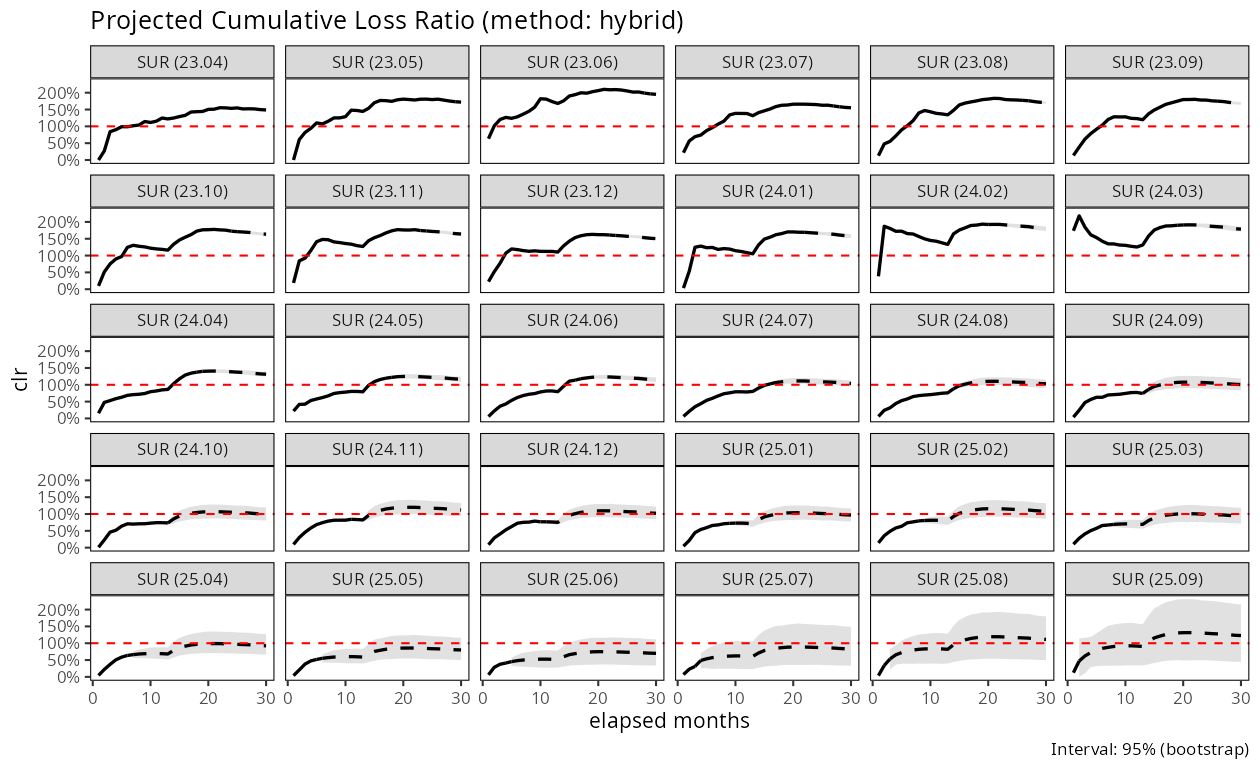
이 예측에서 논의할 몇 가지 특징:
포트폴리오가 현재 손실 상태이다. 23.04에서 24.03 사이의 인수 코호트는 누적 손해율 150-200% 수준에서 안정화되어 손익분기점을 크게 초과한다. 이 초기 코호트들은 이미 관측 기간 동안 \(k^*\) 이후의 성숙 구간까지 도달해 있어, 각 코호트의 예측 점선 부분은 실제 관측된 후기 경험의 연장에 해당한다. 따라서 150-200%라는 수렴 수준은 모형이 인위적으로 만들어낸 값이 아니라 이미 관측된 수준 그대로이다.
최근 인수분은 잠정적 개선을 보인다. 25년 이후 코호트는 100 %에 더 가까운 손해율로 예측되지만, 더 짧은 관측 창 때문에 신뢰구간이 넓다. 프레임워크는 이 불확실성을 정직하게 보고한다: 25.07에서 25.09 코호트에 대한 95 % 부트스트랩 구간은 후기 발전까지 여전히 넓다.
코호트 간 수렴은 강제된 것이 아니다. 각 코호트는 자체 관측 시작값에서 출발해 단계별 재귀식으로 독립적으로 예측된다. 그럼에도 예측 궤적들이 일관된 범위로 모이는 것은 모형이 만들어낸 결과가 아니라 데이터 자체의 성질이다. 실제로 안정 손해율이 존재하는 포트폴리오에서는 이런 수렴이 자연스럽게 기대되며, 프레임워크의 내적 일관성을 간접적으로 확인시켜 준다.
종합하면, 수술담보는 초기 코호트의 손해율 수준이 구조적으로 높지만 최근 코호트에는 개선 조짐이 관측된다. 본 프레임워크는 이 개선이 표본 우연인지 구조적 변화인지의 불확실성까지 신뢰구간으로 정직하게 전달한다.
4.4 단계 4: Triangle 뷰
Triangle은 코호트-경과 구조를 가장 직관적으로 보여주는 표현이다. 먼저 관측된 데이터만을 담은 원본 Triangle을 확인하고, 이어서 예측이 채워진 full Triangle을 살펴보면 프레임워크가 어떤 부분을 채워 넣었는지 한눈에 비교할 수 있다.
4.4.1 관측 Triangle (원본 데이터)
plot_triangle(dev_sur)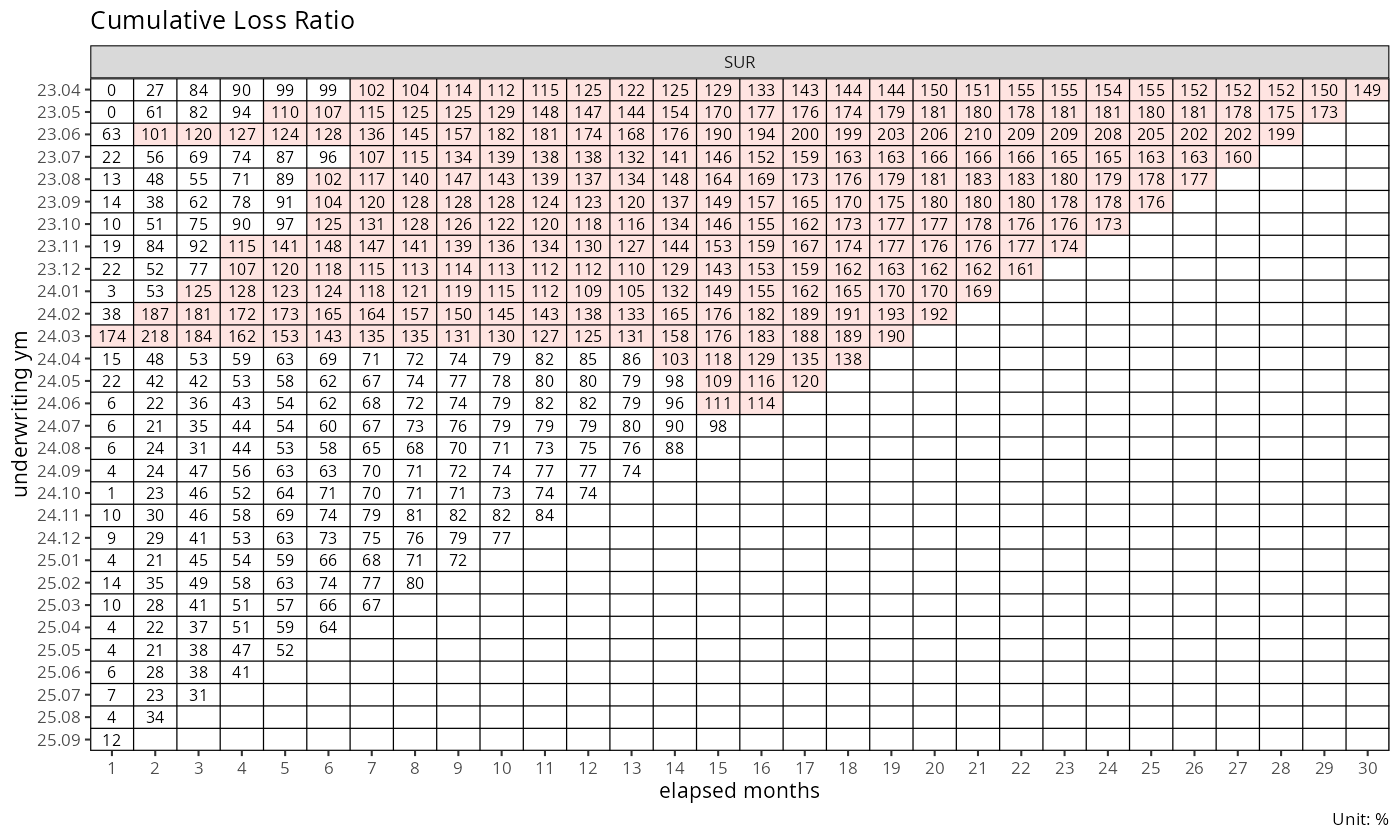
좌상단의 채워진 영역은 실제로 관측된 경험이고, 우하단의 빈 셀이 바로 예측으로 채워야 할 공간이다. 전통적 Chain Ladder가 이 공간을 승법 재귀로만 채우는 반면, 본 프레임워크는 초기 경과 구간을 익스포저 기반 강도로, 성숙 구간을 승법 재귀로 나누어 채운다.
4.4.2 Full Triangle (관측 + 예측)
plot_triangle(fit_sur)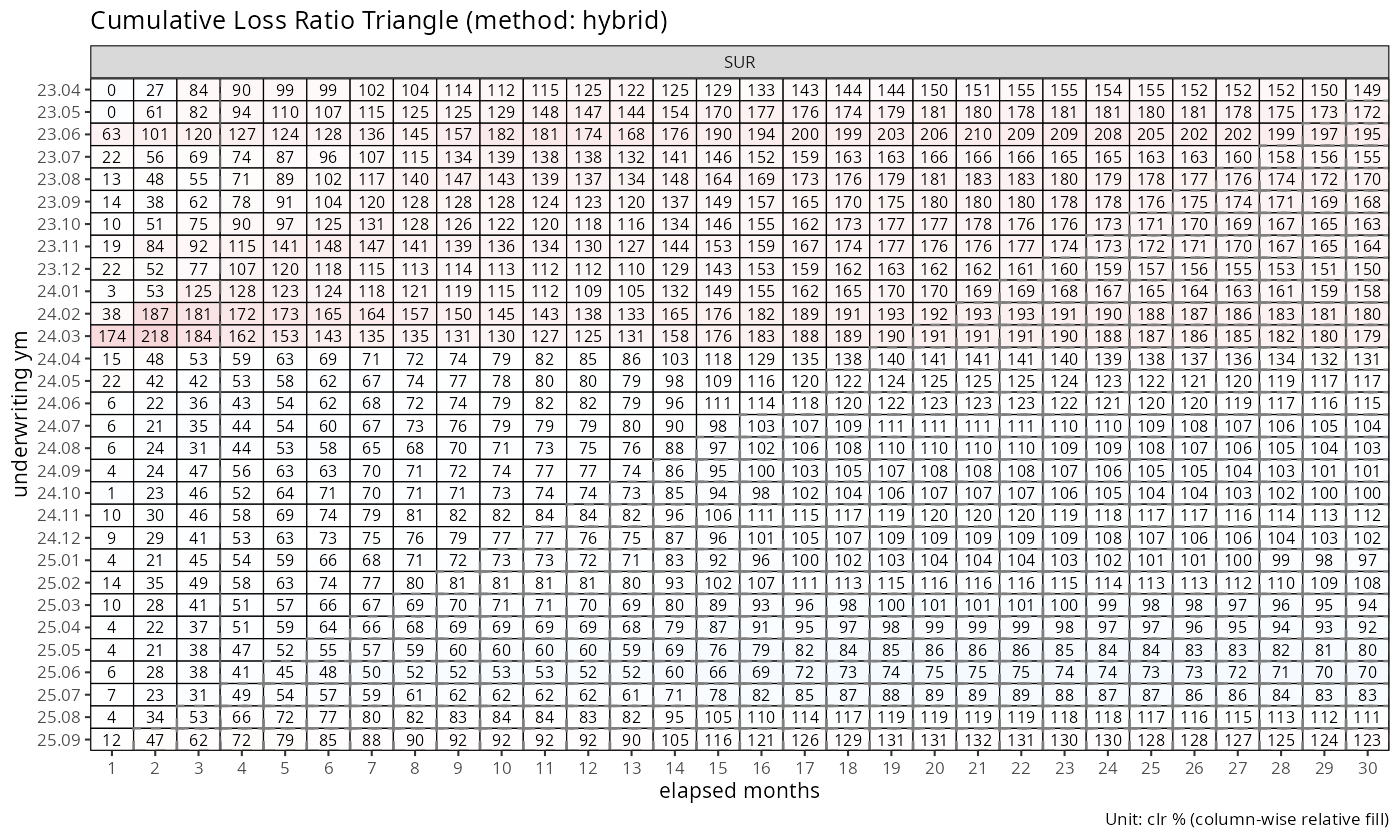
동일한 Triangle에서 행을 따라 읽으면 단일 인수 코호트의 발전 과정이 드러난다. 열을 따라 내려가며 읽으면 같은 발전 연령에서 서로 다른 코호트를 비교할 수 있어, 대각선 효과나 인수 체제 변화를 탐지하는 자연스러운 진단 도구가 된다.
4.5 단계 5: 담보별 진단 뷰
프레임워크는 중간 수량들을 일급 진단 객체로 노출한다. 네 담보를 한꺼번에 비교하면 각 담보의 구조적 차이가 즉시 드러난다.
익스포저 기반 강도 곡선 (\(\hat{g}_k\)). 경과 링크에 대한 증분 손해 강도는 축적된 익스포저 단위당 보험금이 얼마나 빨리 발생하는지를 보여준다. 0을 향한 빠른 감소는 잘 성숙된 포트폴리오와 일관되며, 곡선 모양 자체가 담보별 특성을 드러낸다.
ed <- build_ed(build_dev(data, cv_nm))
plot(ed, type = "summary", scales = "free_y")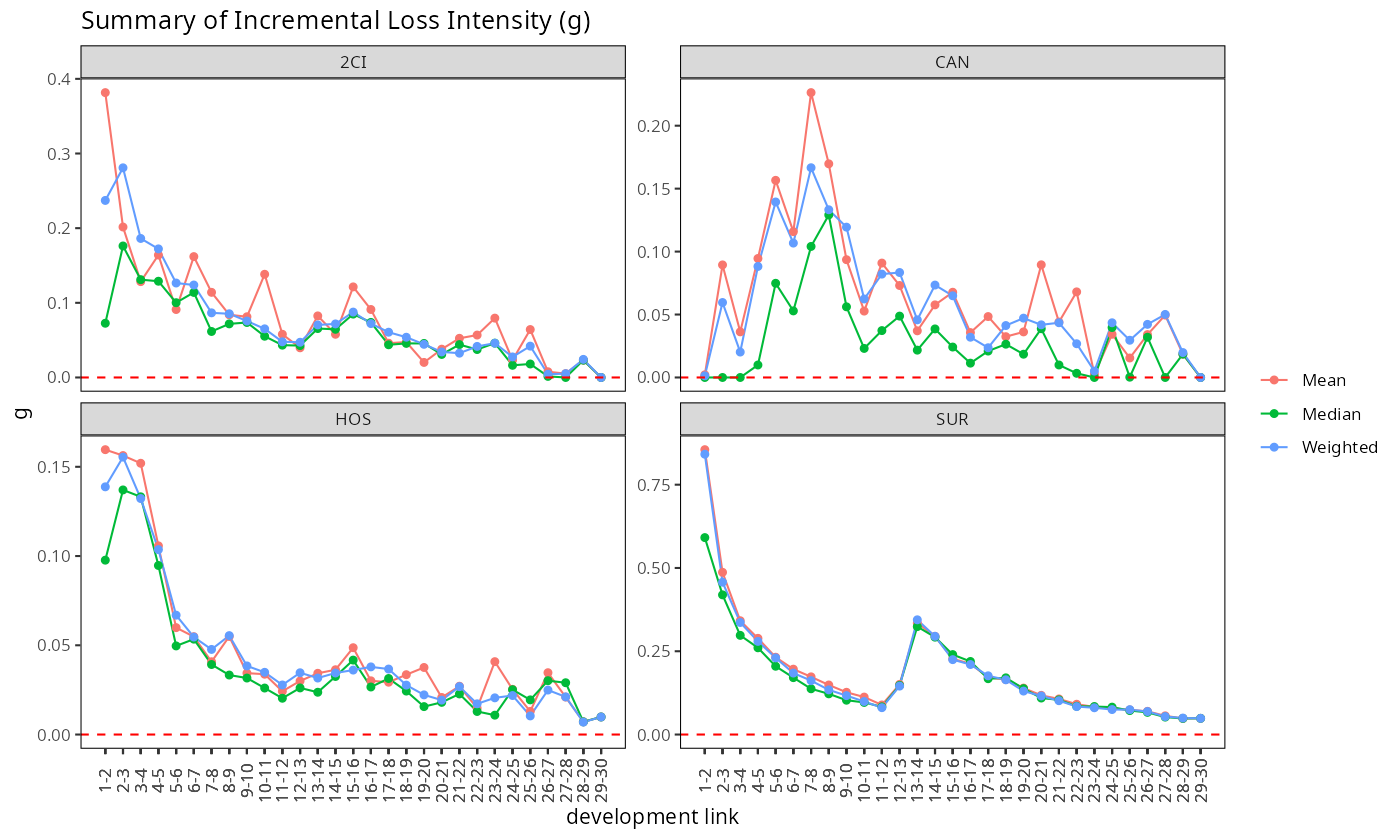
Chain Ladder 안정성 곡선 (\(CV(\hat{f}_k)\)). age-to-age factor의 변동계수는 승법 재귀가 신뢰할 수 있게 되는 시점을 식별한다. 붉은색 수평선은 CV 임계값이고, 음영 영역은 CL 단계에 진입하는 성숙 레짐이다. 세로 점선이 담보별 성숙점 \(k^*\)이다.
plot(build_ata(build_dev(data, cv_nm)), scales = "free_y")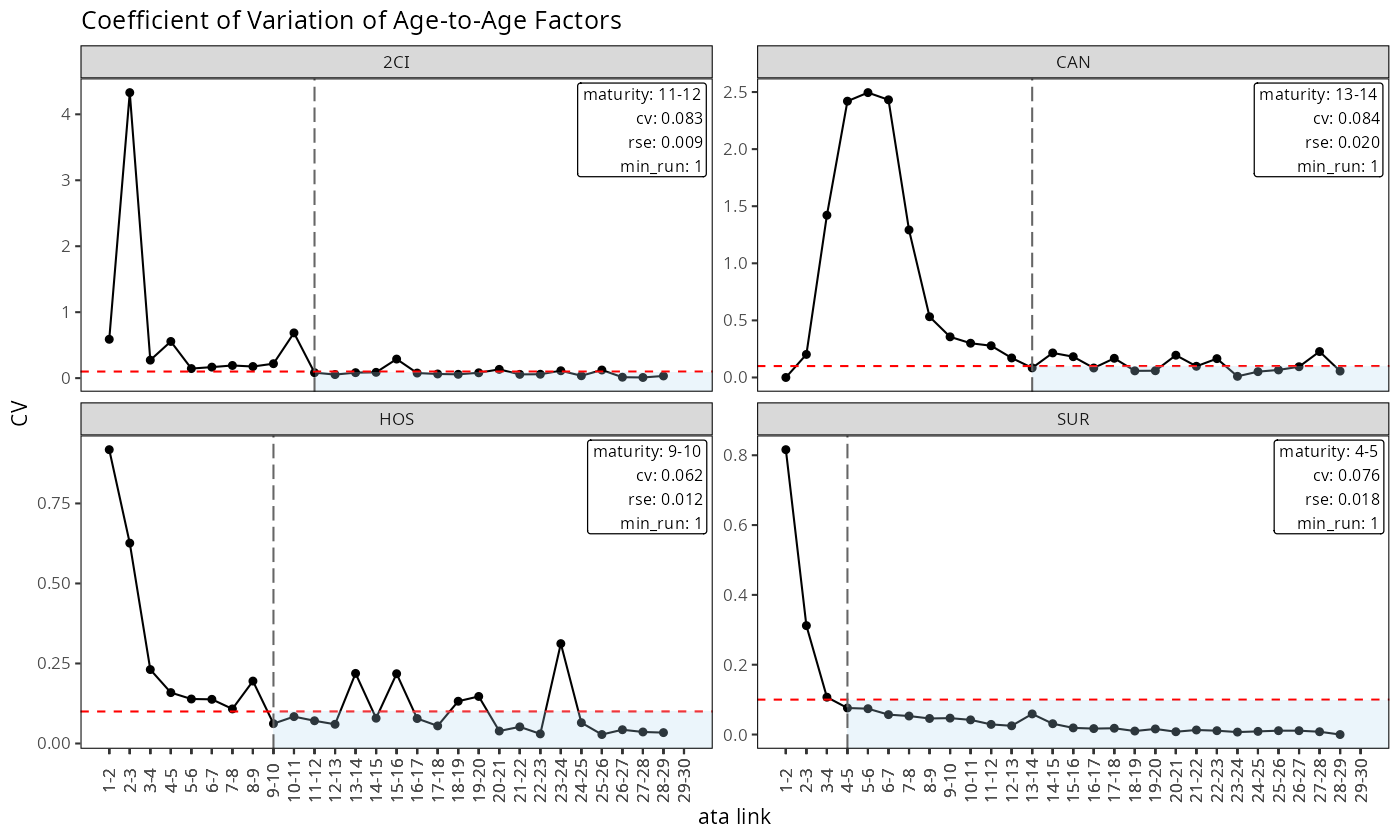
두 그림을 나란히 놓으면 프레임워크가 담보 이질성을 어떻게 수용하는지가 드러난다. \(\hat{g}_k\) 곡선이 빠르게 0에 수렴하는 담보는 자연스럽게 이른 \(k^*\)를 얻고, 잔여 변동이 오래 가는 담보는 늦은 \(k^*\)를 얻는다. 튜닝 파라미터는 동일하지만, 담보별 진단 곡선이 임계값을 만나는 시점이 서로 달라 담보마다 다른 전환점이 산출된다.
4.6 단계 6: 담보 간 비교
동일한 프레임워크가 담보 전반에 균일하게 적용된다. 단일 루프로 각 담보를 적합시켜 성숙점과 안정 손해율에 대한 간결한 요약을 얻는다:
Coverage k_star Stable_CLR
<char> <num> <num>
1: SUR 4 1.282
2: HOS 9 0.387
3: 2CI 11 0.587
4: CAN 13 0.522시각적 개요를 위해, 각 담보 내 코호트 간 예측 손해율을 평균내어 한 패널에 네 궤적을 겹쳐 그리면 포트폴리오 전반의 상대 성과를 즉시 파악할 수 있다:
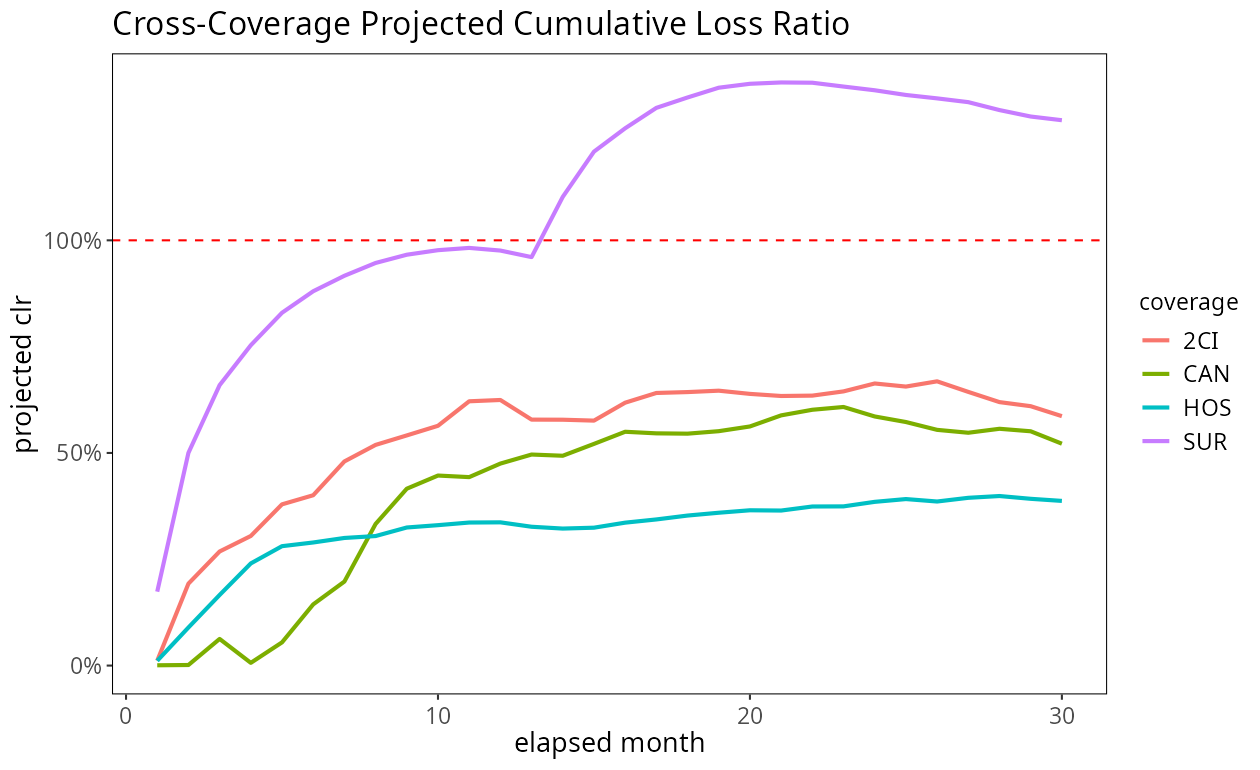
이 overlay는 전적으로 담보별 fit_lr 출력에서 구성되며, 담보 하위집합에 대해 간단하게 재생성할 수 있다. 각 담보는 자기만의 성숙점과 자기만의 안정 손해율을 산출한다. 프레임워크는 담보마다 파라미터를 따로 조정할 필요가 없다 — 동일한 임계값을 써도 담보별로 진단 곡선(CV, RSE 등)이 다르게 나오기 때문에, 그 곡선이 임계값을 통과하는 시점 자체가 담보별로 자연스럽게 달라진다.
4.7 (추가) 코호트 regime의 자동 탐지
plot(dev_sur)의 궤적을 눈으로 보면 “어느 시점부터 다르다”는 인상이 들 때가 많지만, 경계를 육안으로 특정하는 것은 부정확하고 분석자 간 재현성이 떨어진다. 프레임워크는 이를 자동화한 진단 도구 detect_cohort_regime()을 제공한다.
각 인수월 코호트의 CLR 궤적(경과월 \(1, \dots, K\))을 feature vector로 취급한 뒤, 인수 시점 순서로 배열한 다변량 시계열에 변화점 탐지를 적용한다. 세 가지 방법을 지원한다:
ecp— 다변량 비모수 변화점 탐지. 유의수준만 주면 데이터가 지지하는 regime 개수를 자동 결정 (default)pelt— PC1 (첫 주성분)에 대한 빠른 일변량 변화점 탐지. 다중 breakpoint 반환 가능hclust— 시간 순서를 무시한 Ward 계층적 클러스터링. 방법 간 sanity check로 활용
r <- detect_cohort_regime(dev_sur, K = 12, method = "ecp")
print(r)<cohort_regime>
method : ecp
value_var : clr
window (K) : elpm 1, ..., 12
cohorts : 19 analysed (11 dropped)
regimes : 2
breakpoints : 24.04
PC1 / PC2 : 79.8% / 13.2%summary(r)Cohort regime detection summary
method : ecp
value_var : clr
window : elpm 1, ..., 12
cohorts : 19 analysed (11 dropped)
Regimes (2):
1: 23.04, ..., 24.03 (12 cohorts)
2: 24.04, ..., 24.10 (7 cohorts)
Breakpoints: 24.04SUR 데이터에서 세 방법 모두 24.04를 regime 경계로 지목한다. PC1이 코호트 궤적 분산의 약 80 %를 설명하며, pre 군(23.04 ~ 24.03)과 post 군(24.04 이후)이 PC1 방향으로 깨끗이 분리된다.
plot(r)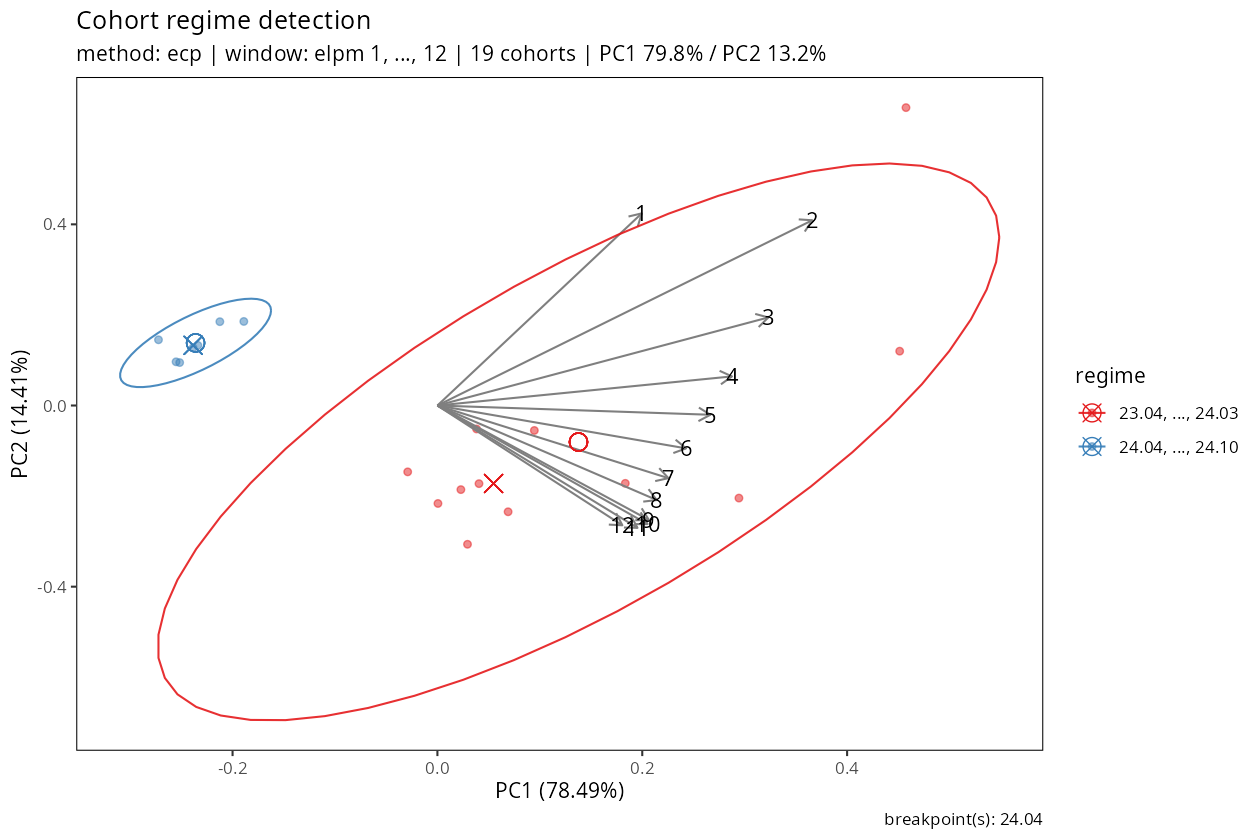
ecp/pelt/hclust 세 방법이 일관되게 24.04를 경계로 지목한다.이 진단은 두 가지 실무적 가치를 제공한다:
- Regime별 분리 적합: 구조적으로 이질적인 두 코호트 집합을 풀링하면 pre 군의 높은 초기 손해율이 post 군까지 섞여 들어가 안정 손해율 추정이 왜곡된다. 탐지된 경계를 기준으로
fit_lr을 regime별로 수행하면 각 regime에 고유한 stable CLR 수준이 분리되어 추정된다. - 요율·인수 체계 변화의 문서화: 자동 탐지된 경계는 요율 개정, 인수 기준 강화, 보험금 처리 정책 변경 등 구조적 사건의 데이터 기반 앵커로 사용된다. 한계 섹션에서 논의하는 premium on-leveling 또는 순노출량 \(V = C^P / r\) 분해가 실제로 필요한 시점을 객관적으로 식별해 주며, 이는 프레임워크 자체의 수정이 아닌 전처리 판단의 근거가 된다.
5 실무적 응용
5.1 안정 손해율의 전략적 활용
본 프레임워크의 주된 산출물은 안정 손해율(stable loss ratio) 이며, 이는 요율 및 상품 전략 의사결정에 데이터 기반 목표를 제공한다.
- 상품별 수익성 진단: 현재 관측 수준과 안정 수준의 차이 — 예컨대 SUR의 150-200% 수렴 — 는 어느 담보가 구조적으로 수익성 관리가 필요한지 즉시 가리킨다.
- 요율 적정성 평가: 안정 손해율이 목표 손해율을 초과하는 담보는 요율 인상, 조건 변경, 언더라이팅 강화의 대상 후보이다. 반대로 안정 수준이 너무 낮은 경우 과도한 요율 부담 가능성을 시사한다.
- 신상품 설계 참고값: 기존 포트폴리오의 안정 손해율 프로파일은 동일 담보군에서 신상품을 기획할 때 pricing assumption을 정당화하거나 재검토하는 기준이 된다.
- 코호트별 비교: 동일 담보 내에서 인수 연도별 안정 손해율이 체계적으로 달라진다면, 인수 체제(underwriting regime) 변화 또는 시장 구성 변화의 신호로 해석할 수 있다.
본 프레임워크는 손해율 수렴 수준과 도달 시점을 추정하는 것을 목적으로 하며, 개별 코호트 최종 손해액의 적립금 산정 자체를 목적으로 하지는 않는다. 준비금 산정이 필요한 경우에는 전통적 Chain Ladder 또는 그 확장이 본 프레임워크와 병행하여 사용될 수 있다.
5.2 포트폴리오 모니터링
ED 단계의 풀링 강도 \(\hat{g}_k\)는 CL 단독 모형의 age-to-age factor에 비해 초기 구간에서 구조적으로 더 안정적인 추정량이다. 이 특성은 포트폴리오 수준 모니터링 지표로 활용될 여지를 제공하지만, 실제 탐지 성능은 담보별 claim 빈도와 누적 관측량에 크게 좌우된다.
Triangle 뷰는 코호트-경과 수준에서 유사한 모니터링을 지원한다. 체계적인 열 단위 패턴의 변화는 추가 조사 필요성을 시사한다.
5.3 투명성과 재현성
본 프레임워크는 친숙한 계리·통계 기법 — 가중최소제곱, 풀링 비율, Mack 형태 분산 — 만으로 구축되며, 전환 규칙이 명시적이고 재현 가능하다. 블랙박스가 없다. 모든 예측 값은 ED 강도, CL 팩터, 또는 관측 시작값까지 한 단계씩 역추적할 수 있다. 어떤 담보에서 왜 \(k^*\)가 그 시점에 잡혔는지, 어느 코호트에서 왜 그 수준의 안정 손해율이 도출되었는지를 기술 문서 수준으로 제시할 수 있다. 그리고 이는 감사 및 경영진 보고 자료에서 설명력을 높이는 방식으로 활용될 수 있다.
5.4 데이터에 내재된 상관 구조 보존과 모형 간결성
본 프레임워크는 코호트 수준의 원본 Triangle을 직접 사용한다. 경과 기간 간·코호트 간·손해 발생 요인 간의 결합 경험 구조가 관측 데이터 자체에 이미 녹아 있으므로, 별도의 모수적 지정 없이도 상관 관계가 자연스럽게 보존된다. 추가 모수의 수가 작아 소규모 데이터에서도 과적합 위험이 낮다.
참고로 빈도·심도 분해나 2-factor 리스크 모형과 같이 손해 발생 과정을 여러 요인으로 분해한 뒤 독립성 가정 아래 결합하는 Parameter 기반 접근은, 요인들이 실제로 상관되어 있는 경우 상관 구조가 모형 밖으로 빠져나가 편향을 초래할 수 있다. 본 프레임워크는 분해(Decomposition) 대신 Triangle을 통째로 다루기 때문에 이 문제를 구조적으로 회피한다.
6 구현
패키지의 공개 API는 핵심 함수 몇 개로 간결하게 구성된다.
library(lossratio)
# 1. 발전 구조 생성
dev <- build_dev(data, group_var = cv_nm) # 담보, 상품, 채널 등
# 2. 혼합 손해율 모형 적합
fit <- fit_lr(
dev,
method = "hybrid",
bootstrap = TRUE,
B = 1000,
seed = 42
)
# 3. 시각화
plot(fit, type = "clr") # 신뢰구간이 포함된 예측 손해율
plot(fit, type = "closs") # 예측 누적 손해액
plot_triangle(fit) # Triangle 히트맵
# 4. 검토
print(fit) # 요약 (검출된 k* 포함)
fit$full # 셀 수준 예측과 CI
fit$maturity # 그룹별 성숙점패키지는 중간 객체(build_ata, build_ed)와 그 적합 결과(fit_ata, fit_ed)도 노출하여 구성요소를 직접 검토하고자 하는 사용자를 지원한다.
7 한계와 책임 있는 사용
프레임워크는 한계를 의도적으로 투명하게 제시한다.
유효 데이터의 가용성. 본 프레임워크는 충분한 수의 코호트와 충분한 길이의 관측 경험이 전제돼야 동작한다. 구체적으로 (i) 각 경과 링크에 기여하는 코호트가 복수여야 \(\hat{g}_k\) 풀링이 의미를 가지고, (ii) age-to-age factor 시퀀스가 안정화되는 구간이 실제로 관측돼야 \(k^*\)를 경험적으로 탐지할 수 있으며, (iii) 입력 데이터의 기준 — 보고 기준(reported), 지급 기준(paid), 발생 기준(incurred) — 이 전 코호트에 걸쳐 일관돼야 한다. 특히 발생 기준을 사용할 경우 IBNR 재추정이나 case reserve 사후 수정으로 과거 \(C^L_{i,k}\) 값이 흔들리면 추정이 편향되며, 보고 기준을 사용하면 과거 셀이 확정되어 이 문제가 발생하지 않으므로 실무에서는 보고 기준이 기본 옵션으로 권장된다. 포트폴리오가 너무 작거나, 관측 창이 너무 짧거나, 데이터 기준이 일관되지 않은 경우 추정 자체가 불가능하거나 극단적으로 불안정해지므로, 데이터 정합성 검토가 분석에 선행돼야 한다.
성숙점의 데이터 의존성. \(k^*\)는 예측에 쓰는 그 데이터로부터 추정되므로, 외부에서 독립적으로 주어진 값이 아니다. 따라서 \(k^*\) 자체도 표본에 따라 달라지는 확률변수인데, 예측 신뢰구간을 계산할 때는 이를 고정된 값으로 취급한다 — 그 결과 \(k^*\)의 표본 변동성이 불확실성 추정에서 빠진다. 또한 포트폴리오에 따라 CV·RSE 곡선이 어느 지점에서 임계값을 뚜렷하게 돌파하는 경우도 있고, 완만하게 줄어들기만 해서 전환점이 불명확한 경우도 있다. 후자의 경우 \(k^*\)가 임계값의 미세한 차이에 따라 크게 달라지므로, 임계값 선택에 대한 민감도를 검토해야 한다.
전환점에서의 분산 불연속성. 평균 예측은 \(k^*\)에서 연속이지만 분산 공식은 성격을 바꾼다: ED 단계에서 가법적, CL 단계에서 승법적. 이는 CI 폭이 비단조적이 되는 구조적 원인이다 (ED에서 좁아졌다가 CL에서 다시 넓어짐). 불확실성 띠를 제시하는 실무자는 이 특징을 인지해야 한다. 분산 연속 확장은 활발한 향후 연구 영역이다.
모형 내 불확실성만 반영. 모든 신뢰구간 — 분석적 및 부트스트랩 — 은 모형이 올바르다는 조건 하의 불확실성을 정량화한다. 레짐 변화, 파라미터 드리프트, 모형 오특정(misspecification)으로부터 오는 구조적 불확실성은 포착되지 않는다. 장기 수평선 예측은 이 점을 염두에 두고 해석해야 하며, 중요한 의사결정에는 외부 기준(포트폴리오 수준 앵커, 업계 데이터)으로 모형 내 분석을 보완해야 한다.
코호트 간 독립성. 분산 공식은 코호트의 조건부 독립을 가정하며, 이는 Mack의 Chain Ladder에서 계승된다. 대각선 효과(diagonal effect) — 제도 변경, 보험금 정산 변경, 의료비 인플레이션 등 같은 달력 시점에 모든 코호트가 공통으로 받는 영향 — 는 이 가정을 위배할 수 있다. 패키지의 진단 도구는 이러한 패턴을 드러내지만, 현재의 분산 공식은 대각선 상관을 전파하지 않는다.
요율 변경과 보험료 규모의 오염. 프레임워크는 관측 기간 내 요율 체계의 안정성을 암묵적으로 가정한다. 보험료 규모는 \(C^P = V \cdot r\) (순노출량 \(\times\) 위험 요율)로 분해되는데, 관측 기간 중 요율 개정이 발생하면 \(r\)의 변동이 \(C^P\)에 흡수되어 풀링된 강도 추정이 오염될 수 있다. 이 경우 premium on-leveling — 공통 기준 요율 \(r_{\text{base}}\)로의 재조정 — 또는 순노출량 \(V = C^P / r\)로의 분해를 선행 전처리로 수행하는 것이 권장된다. 특히 새로 출시되는 상품의 a priori 안정 손해율 추정은 과거 유사 상품의 on-leveled 혹은 V-based 이력을 입력으로 사용하는 방식이 적절하며, 이는 프레임워크의 수학적 재정식화가 아니라 데이터 전처리 영역에서 다룰 사안이다.
8 맺음말
Chain Ladder는 손해보험에 널리 쓰이는 계리 모형이지만, 장기 건강보험의 손해율 예측은 그 설계 전제와 구조적으로 다른 문제이다. 본 문서에서 제안한 Stage-Adaptive Chain Ladder는 Chain Ladder의 강점인 성숙 코호트의 승법 재귀는 그대로 두고, 약점인 초기 단계에서는 코호트별 누적 손해액 대신 포트폴리오 수준 익스포저를 기준점으로 삼는다.
프레임워크는 추측성 최종 손해액 추정을 경험적 안정 손해율 추정으로 대체하고, 어떤 코호트가 이미 성숙해 자체 경험으로 말할 수 있고 어떤 코호트가 여전히 포트폴리오 수준 정보를 필요로 하는지 명확히 하며, 그 모든 과정에 대한 투명하고 재현 가능한 도구를 제공한다. 초기·성숙 구간을 구분 없이 하나의 방식으로 예측하는 접근보다 장기 수평선의 손해율 추정에 더 정직하고 유용한 기반이라고 판단한다.
자세한 기술적 유도 과정은 패키지에 동반한 Note From Exposure to Experience: A Stage-Adaptive Chain Ladder for Long-Duration Health Insurance에 수록하였다.